
Данная статья входит в альманах искусственного интеллекта №7 – Обучение с подкреплением.
Рекомендательные системы - ретроспектива
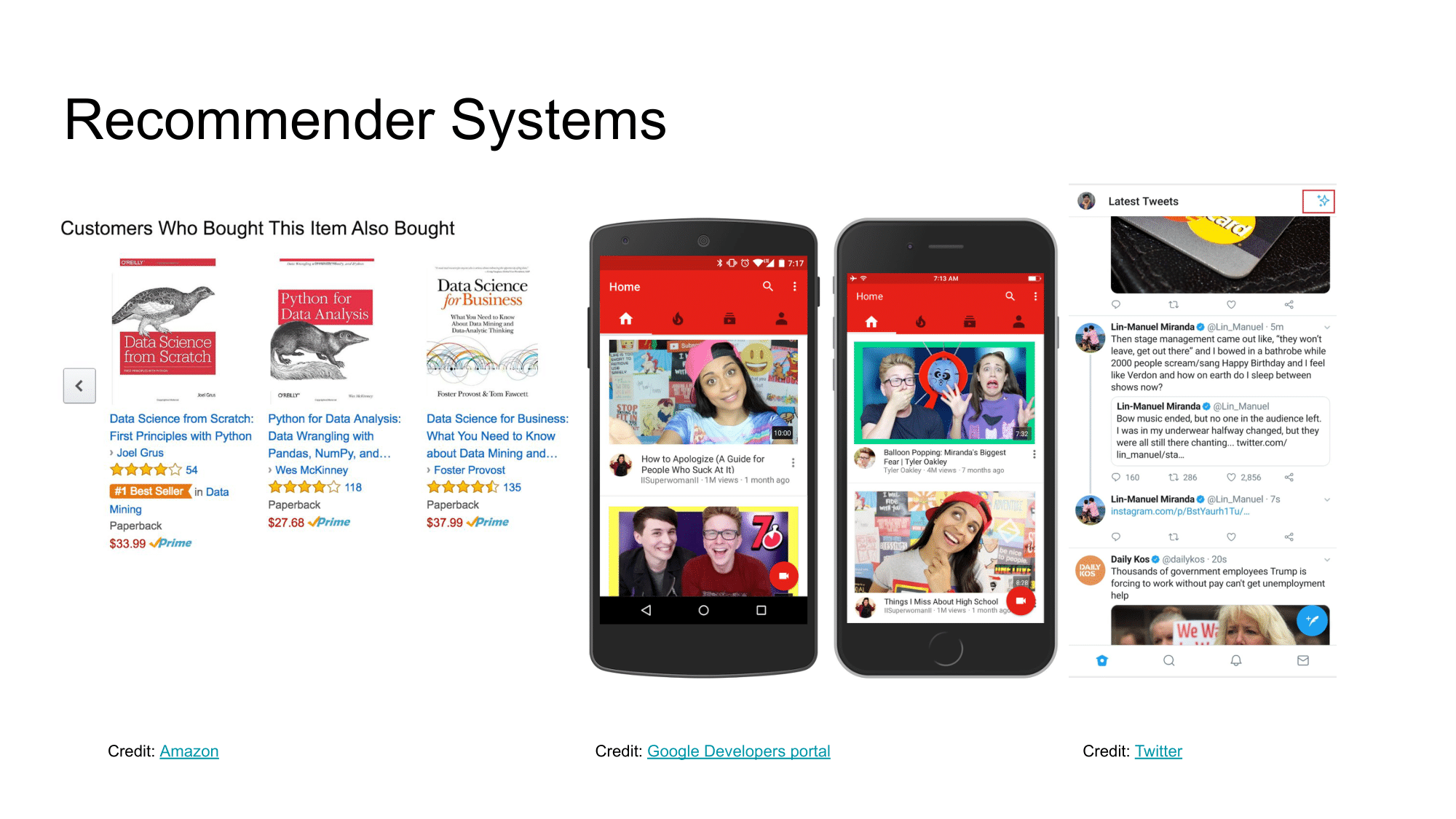
Вы наверняка уже знаете, что рекомендательные системы повсюду окружают вас:
- они подбирают и ранжируют товары в маркет-плейсах (Amazon, Yandex) и фильмы (Netflix, Disney), чтобы найти самое релевантное по вашему запросу,
- они составляют подборки и выбирают следующий трек/видео на Spotify/Youtube, чтобы удовлетворить ваши личные предпочтения,
- они фильтруют вашу ленту, когда вы листаете Twitter/Instagram/VK, чтобы показать только самое важное для вас.
Как результат, рекомендательные системы сегодня влияют почти на все аспекты взаимодействия с пользователем. А текущие требования по персонализации пользовательского опыта и прогресс в области машинного обучения постоянно толкают область к новым научным свершениям.

Наиболее стандартным и наиболее популярным методом в рекомендательных системах является коллаборативная фильтрация, а точнее - метод матричных разложений.
Идею коллаборативной фильтрации можно описать следующим образом (положим мы делаем рекомендательную систему для книжного магазина):
- если пользователям А и Б обоим нравятся книги X, Y, Z,
- и пользователь А оставил положительный отзыв про новую книгу K,
- то логично порекомендовать ее пользователю Б,
- из предположения, что их интересы похожи.

Практическая реализация такой идеи - метода матричных разложений - также довольно проста:
- мы собираем матрицы взаимодействия пользователей с товарами,
- и пытаемся аппроксимировать эту матрицу с помощью обучаемых представлений для пользователей и для товаров,
- чтобы при перемножении векторного представления пользователя А и векторного представления товара Б, можно было получить их приближенный рейтинг “совместимости” из нашей матрицы.
По итогу работы метода, мы хотим
- Во-первых - научиться точно предсказывать текущие рейтинги совместимости, о которых мы уже знаем,
- А во-вторых - выносить предположения о пропущенных/незаполненных значения в этом матрице и использовать эти предположения для рекомендаций.
Рекомендательные системы и влияние ленты
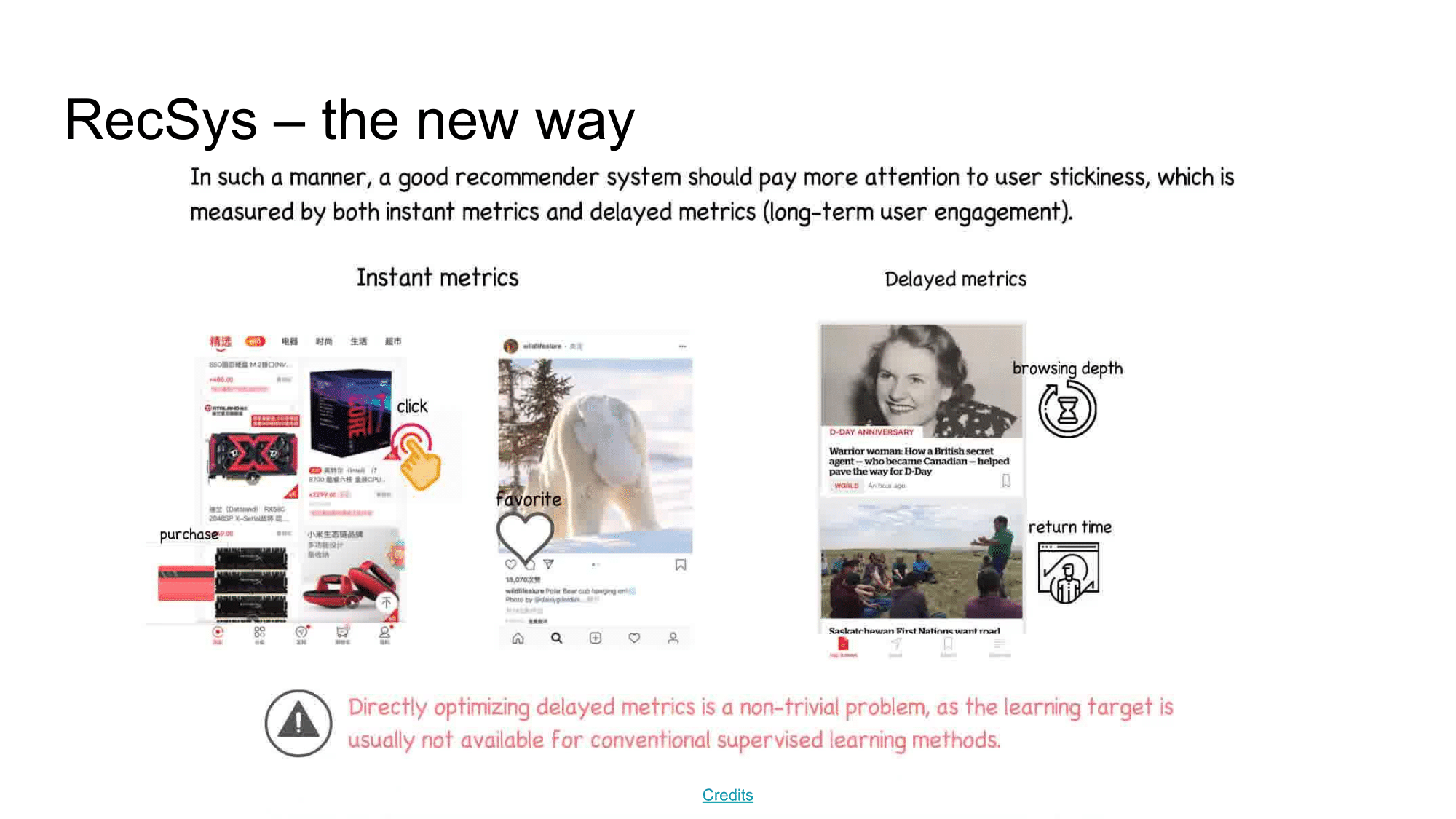
Сегодня механизм взаимодействия с пользователем меняется от статического user-item-корзина на динамическую живую ленту. При таком подходе становится все сложнее применять методы коллаборативной фильтрации. Если точнее, то переход на такой динамический метод взаимодействия с пользователем поднял новые вопросы при использовании рекомендательных систем. Например,
- как персонализировать опыт пользователя в его текущую сессию? как учитывать не только его глобальные предпочтения, а понимать его текущие, краткосрочные цели?
- как последовательность рекомендаций влияет на его опыт за сессию взаимодействия с сервисом?
- как его текущий опыт за сессию повлияет на его будущее использование сервиса? (отложенный reward из RL)
Все эти вопросы привели к появлению нового типа рекомендательных систем - collaborative interactive recommenders (CIRs). CIR - это рекомендательные системы, которые оптимизируют последовательность взаимодействий с пользователем, а не одну конкретную рекомендацию.
Разрабатывая CIR рекомендательные системы в парадигме Deep Learning, Supervised Learning, можно столкнуться с рядом практических сложностей. В это же время подход Reinforcement Learning является де факто стандартом для оптимизации последовательностей принимаемых решений, и отлично расширяется до фреймворка взаимодействия рекомендательной системы с пользователя.
RL in RecSys

По словам Craig Boutilier использование RL в RecSys, позволит понимать и удовлетворять потребности пользователей, используя более естественное и прозрачное взаимодействие. За последние пару лет произошел большой прогресс в использовании методов RL на разнородных данных - картинках, текстах, звуках. Кроме этого, фреймворк обучения с подкреплением позволяет напрямую оптимизировать конечные метрики без использования дифференцируемых прокси-метрик.
Сейчас происходит плавный переход от Collaborative Filtering через Collaborative Interactive Recommenders к фреймворку обучения с подкреплением в задаче рекомендаций.
В этом обзоре хотелось бы показать сферу применимости RL в RecSys, а также рассказать о сходствах этих двух областей. Для этого сперва пробежимся по нескольким статьям, а в конце подведем краткий итог их применимости на бою. Тему использования многоруких бандитов оставим за кадром и больше сфокусируемся на использовании Deep Reinforcement Learning.
Deep Reinforcement Learning in Large Discrete Action Spaces
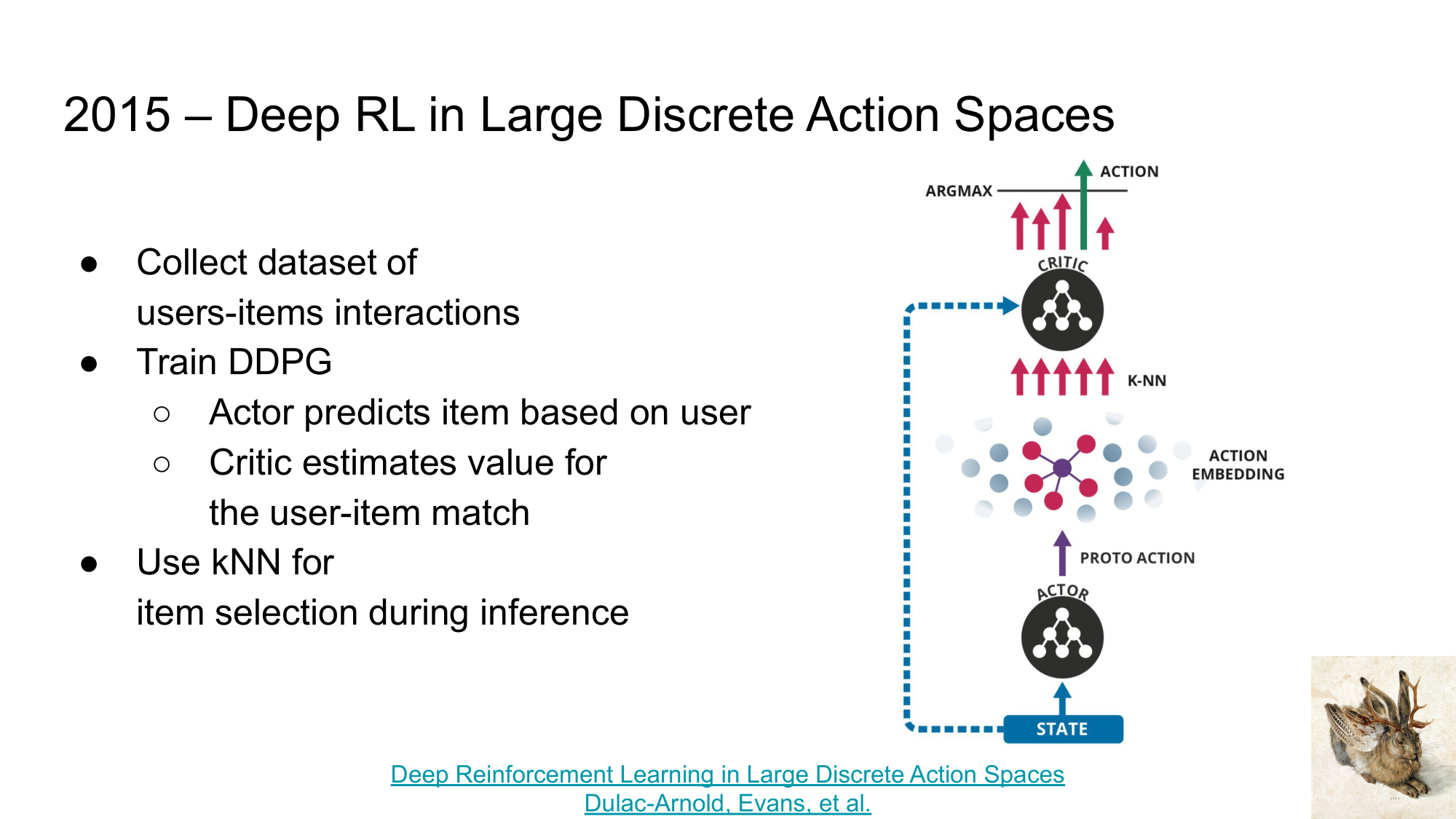
Первая статья, про которую хочется рассказать при переходе от RecSys к RL является “Deep Reinforcement Learning in Large Discrete Action Spaces” и алгоритм Wolpertinger.
Краткая суть статьи заключается в следующем:
- давайте соберем датасет взаимодействий пользователей с товарами (как и в методе факторизации матриц)
- на этом датасете обучим DDPG (Deep Deterministic Policy Gradient), в котором
- задача Actor - по представлению пользователя предсказывать наиболее релевантное представление товара, которое тому требуется порекомендовать
- задача Critic - по представлению пользователя и рекомендованного Actor товара - оценить полезность такой рекомендации
- после такого обучения, мы можем
- “обучить” kNN на нашей базе товаров, которые хотим рекомендовать
- использовать Actor для генерации “примерного” представления товара для рекомендации
- через kNN находить topK рекомендаций из нашей базы, наиболее близкие к “примерному”
- и переранжировать их с помощью Critic, для выбора наиболее релевантного.
Этот подход прост в реализации и является своего рода переходной точкой между факторизацией матриц и использования обучения с подкреплением для рекомендаций.
PS. Пример Wolpertinger вы можете найти на нашем курсе.
Deep Reinforcement Learning based Recommendation with Explicit User-Item Interactions Modeling
Следующая статья, на которую хочется обратить внимание – “Deep Reinforcement Learning based Recommendation with Explicit User-Item Interactions Modeling”.
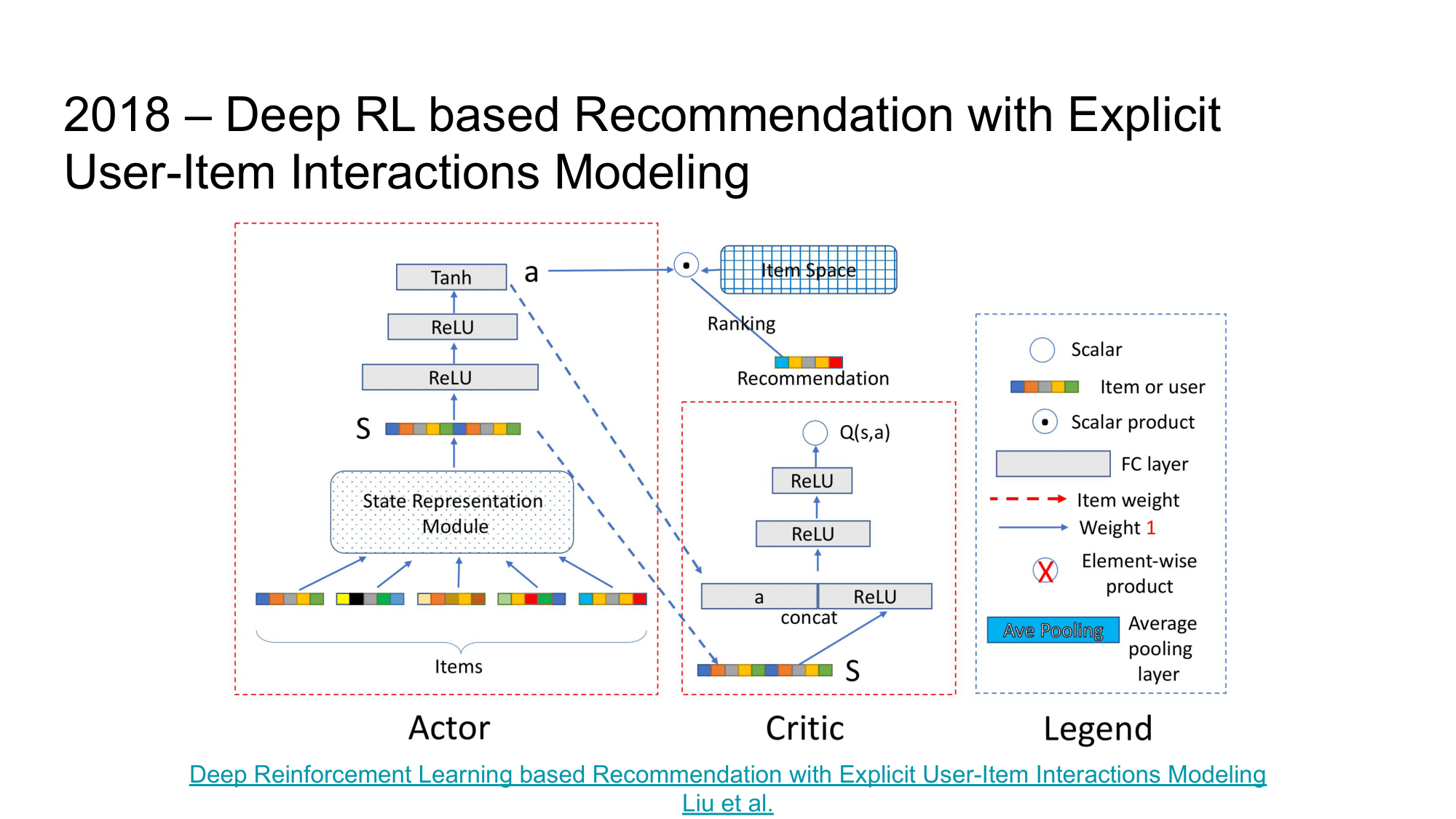
Как и в предыдущей статье, здесь используется Actor-Critic подход в обучении. Actor тут принимает на вход описание пользователя и набор товаров для рекомендации, а выдает скоры, ранжирующие эти товары для показа пользователю. Critic в свою очередь по такому ранжировавнию и состоянию Actor пытается предсказать ценность подобного ранжирования.
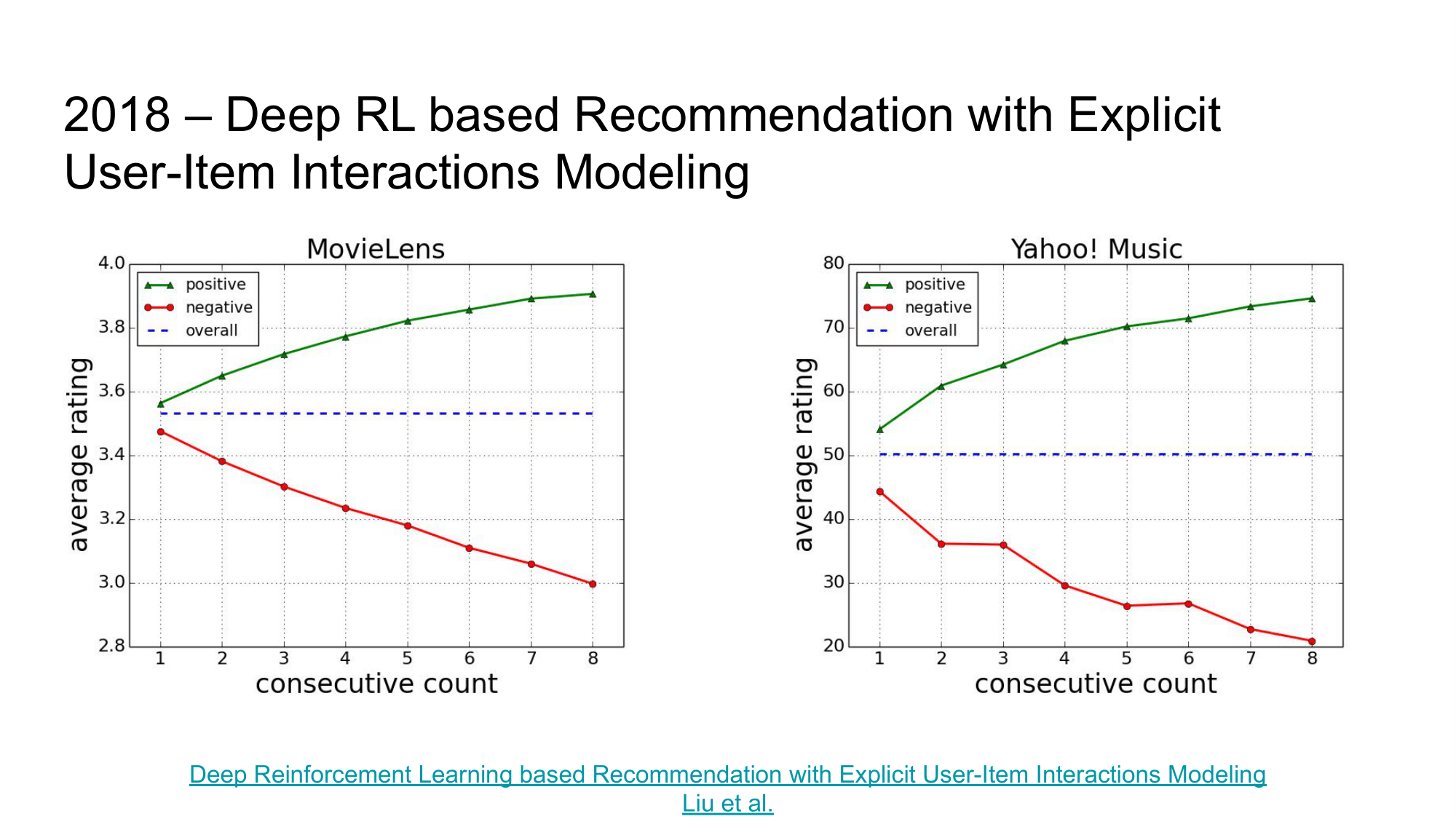
И хотя в этой статье используется другой архитектурный подход по использованию Actor-Critic в задаче рекомендаций, показательной частью этой статьи также является вводное исследование. Авторы нашли взаимосвязь между удовлетворенностью пользователя последовательностью рекомендаций и оценкой следующего предложения, т.е.:
- если пользователю нравится последовательность предложенных рекомендации, он с большой вероятностью позитивно отреагирует и на следующее предложение
- если пользователю не нравятся последовательность предложенных рекомендации, он с большей вероятностью негативно оценит и следующее предложение.
Это исследование показывает, что рекомендательным системам важно уметь быстро адаптироваться под текущие желания и настроение пользователя, а не думать только в контексте его “глобальных предпочтений”.
Top-K Off-Policy Correction for a REINFORCE Recommender System
Касательно прорывов в области индустриального использования RL в рекомендательных системах, хочется отметить статью “Top-K Off-Policy Correction for a REINFORCE Recommender System”.
В данной статье авторы сумели не только предложить ряд подходов по адаптации методов On-policy RL для RecSys, но также показали статистически значимые результаты при использовании такой системы для рекомендаций на YouTube.
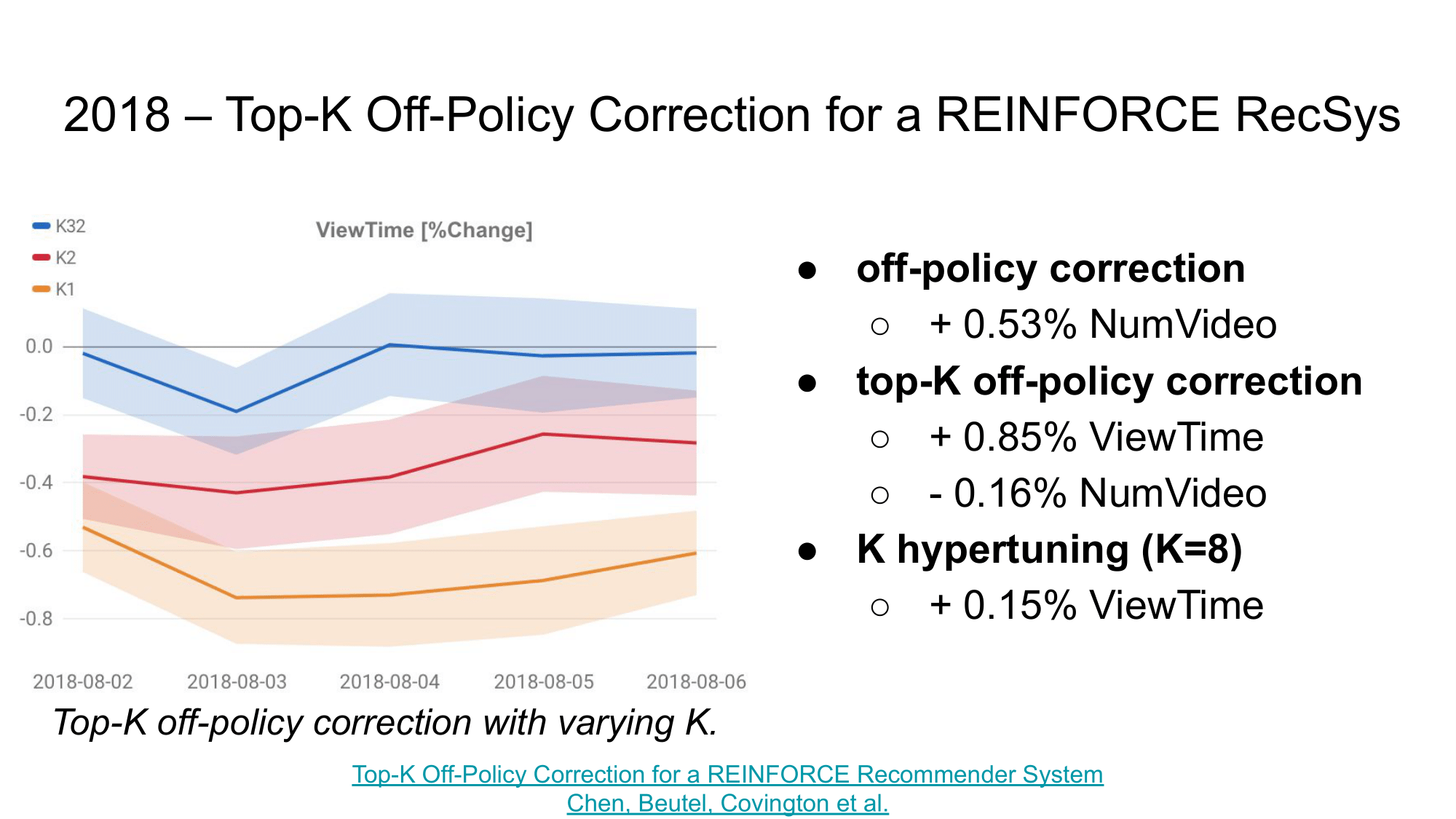
Из наиболее интересных теоретических и практических результатов можно выделить:
- использование on-policy RL алгоритма REINFORCE для задачи рекомендаций,
- введение off-policy correction для адаптации этого алгоритма к off-policy обучению по логам взаимодействий с пользователями – дало прирост по количеству просматриваемых видео на 0.53%,
- введение top-K off-policy correction для адаптации под top-K рекомендаций – увеличило среднее время просмотра за сессию (ViewTime) на 0.85%, но снизило количество просматриваемых видео на 0.16%,
- перебор параметра K – дополнительно увеличил ViewTime на 0.15%.
Как результат, авторам удалось повысить, и количество просматриваемых видео, и среднее время просмотра за сессию. Данные результаты являются важным экспериментальным доказательством возможности использования обучения с подкреплением в таких больших рекомендательных системах как Youtube с миллионами пользователей и миллионами документов для рекомендаций.
Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
Продолжая развивать тему использования RL в рекомендациях на Youtube, авторы пошли дальше и в своей следующей статье “Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology” предложили подробный разбор предложенных ими методов.
С учетом глубины статьи — она занимает около 30 страниц — мы опустим ее “краткое описание” и посоветуем лишь ознакомиться с ней действительно интересующимся читателям.
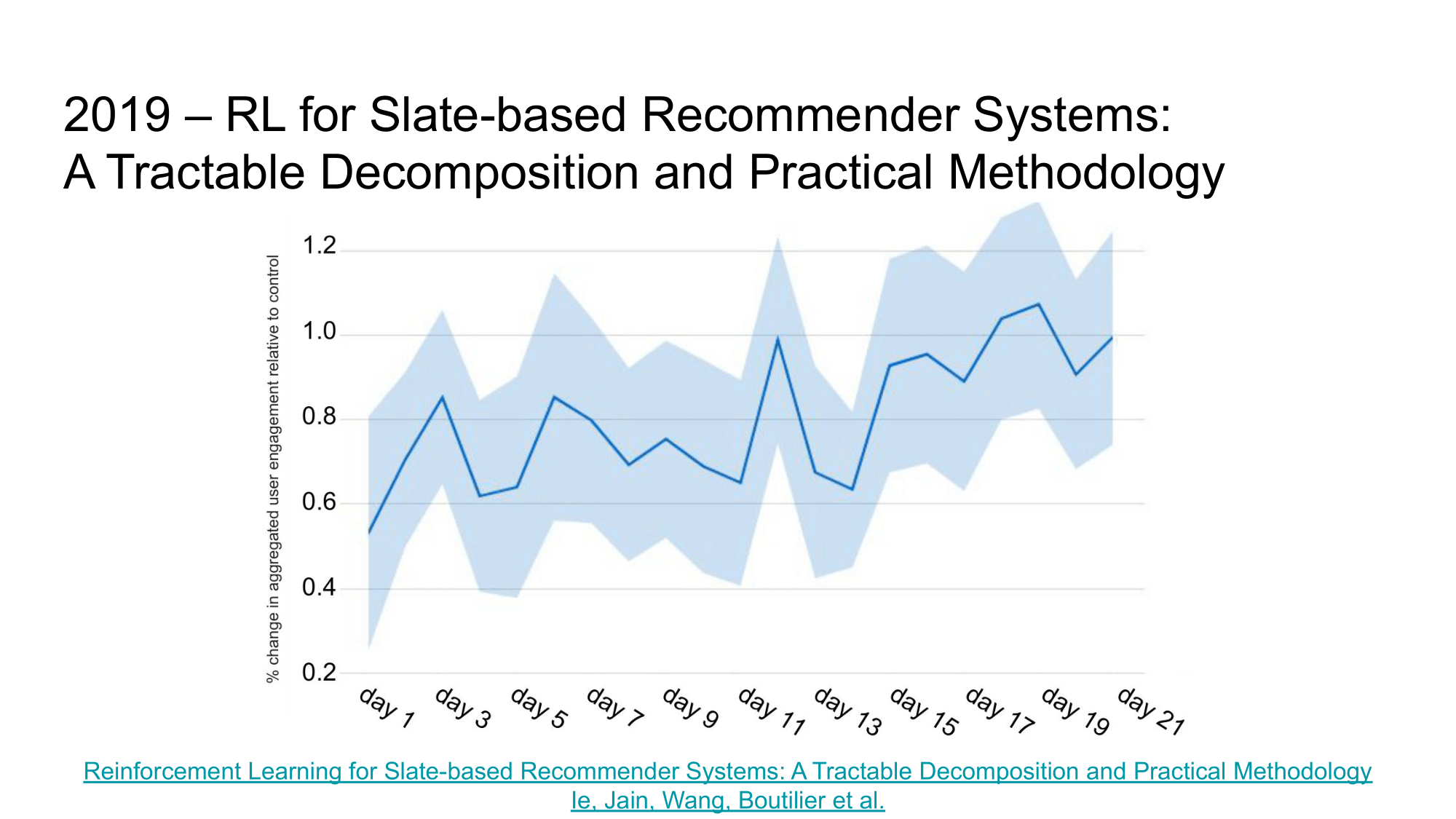
Однако, давайте рассмотрим практические результаты. В своей работе авторы сравнивают 2 подхода к рекомендациям на Youtube:
- MYOP-TS, который оптимизирует краткосрочный отклик от пользователя – pCTR,
- SARSA-TS LTV, который оптимизирует long-term user engagement.
По итогам экспериментов SARSA-TS LTV удалось показать прирост в 1% по user engagement метрике. Эта статья еще раз доказывает возможность прямой оптимизации недифференцируемых LTV метрик с помощью обучения с подкреплением в задаче рекомендаций (даже в таких больших системах как Youtube).
RecSim: A Configurable Simulation Platform for Recommender Systems
Напоследок, хотелось бы обратить внимание на статью “RecSim: A Configurable Simulation Platform for Recommender Systems”, которая неявно продолжает предыдущие исследования.
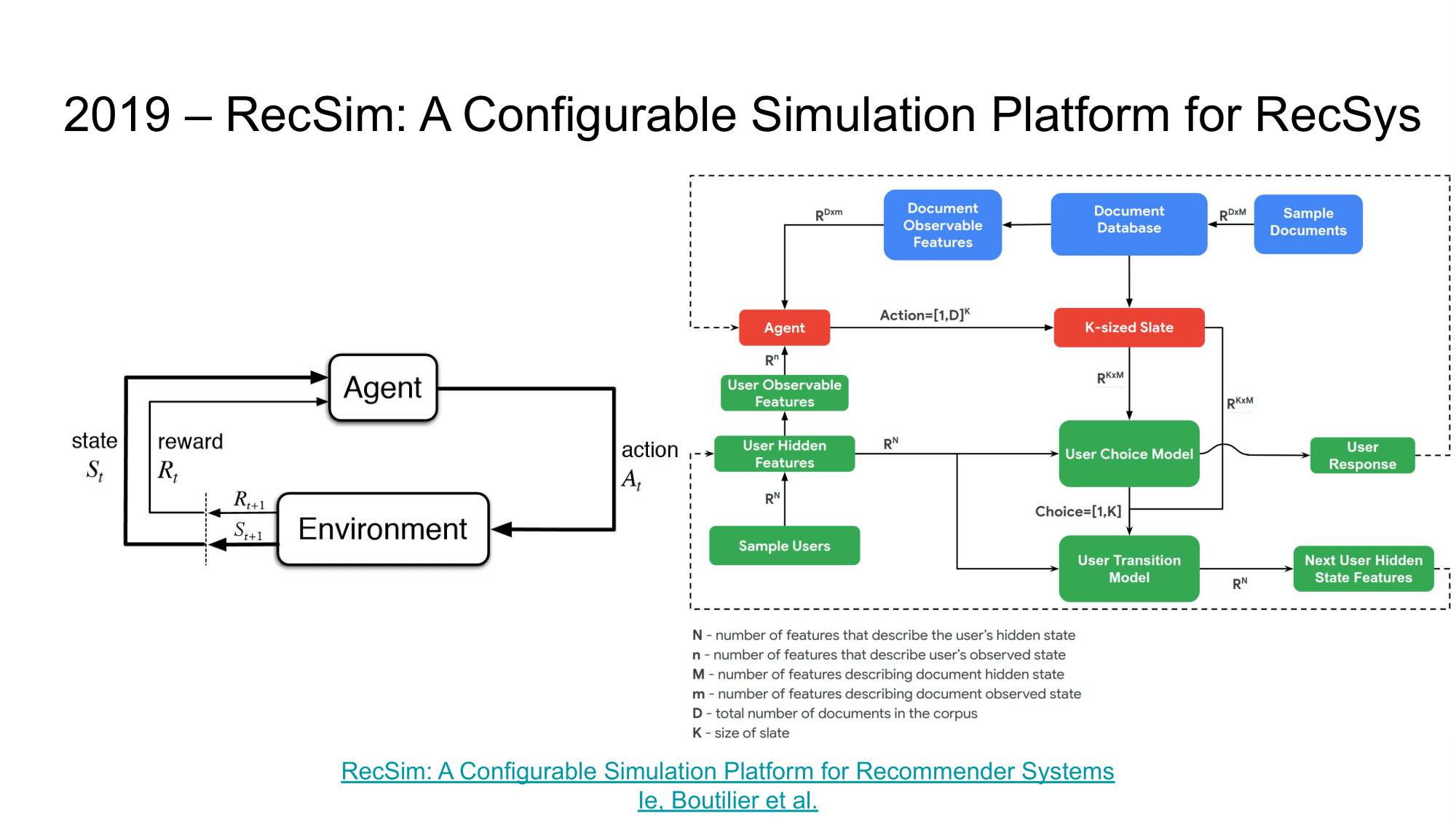
Одна из проблем применения RL в рекомендациях заключается в том, что большинство исследований разрабатываются и оцениваются с использованием статических наборов данных, которые не отражают последовательного взаимодействия рекомендательной системы с пользователем. Это затрудняет оценку даже базовых алгоритмов RL, особенно когда дело доходит до рассуждений о долгосрочных последствиях некоторой новой политики рекомендаций. Возможность моделировать поведение пользователей в некоторой среде, а также разрабатывать и тестировать новые алгоритмы рекомендаций, в том числе с использованием RL, может значительно ускорить исследования применимости RL в RecSys.
В этой статье авторы представляют RecSim - RL среду, которая имитирует взаимодействие рекомендующего агента со средой, состоящей из модели пользователя, модели документа и модели выбора пользователя. Более подробное описание можно найти на github. Хочется верить, что благодаря подобным библиотекам, исследования RL в RecSys станут доступнее, понятнее и стандартизованнее благодаря большему комьюнити.
Conclusion
Из приведенных статей видно, что исследования применения RL в рекомендательных системах не только не стоят на месте, а уже активно используются в больших проектах/продуктах и уже помогают нам с вами.
Нужно ли использовать RL в ваших рекомендациях? Конечно же…. надо тестировать и проверять. Отталкивайтесь от условий и требований задачи, а не от технологий – сравнивайтесь с бейзлайнами, начинайте с простых решений (разберите пример RecSim with Wolpertinger с курса), ознакомьтесь со всеми статьями из этого обзора, оцените сложность реализации и полезность подобной системы.

А мы надеемся, что этот обзор стал для вас хорошим введением в область RecSys.RL. Релевантных и долгосрочных рекомендаций вам!