
This article is included to Artificial Intelligence Almanac #7 - Reinforcement Learning.
Recommender systems - a retrospective
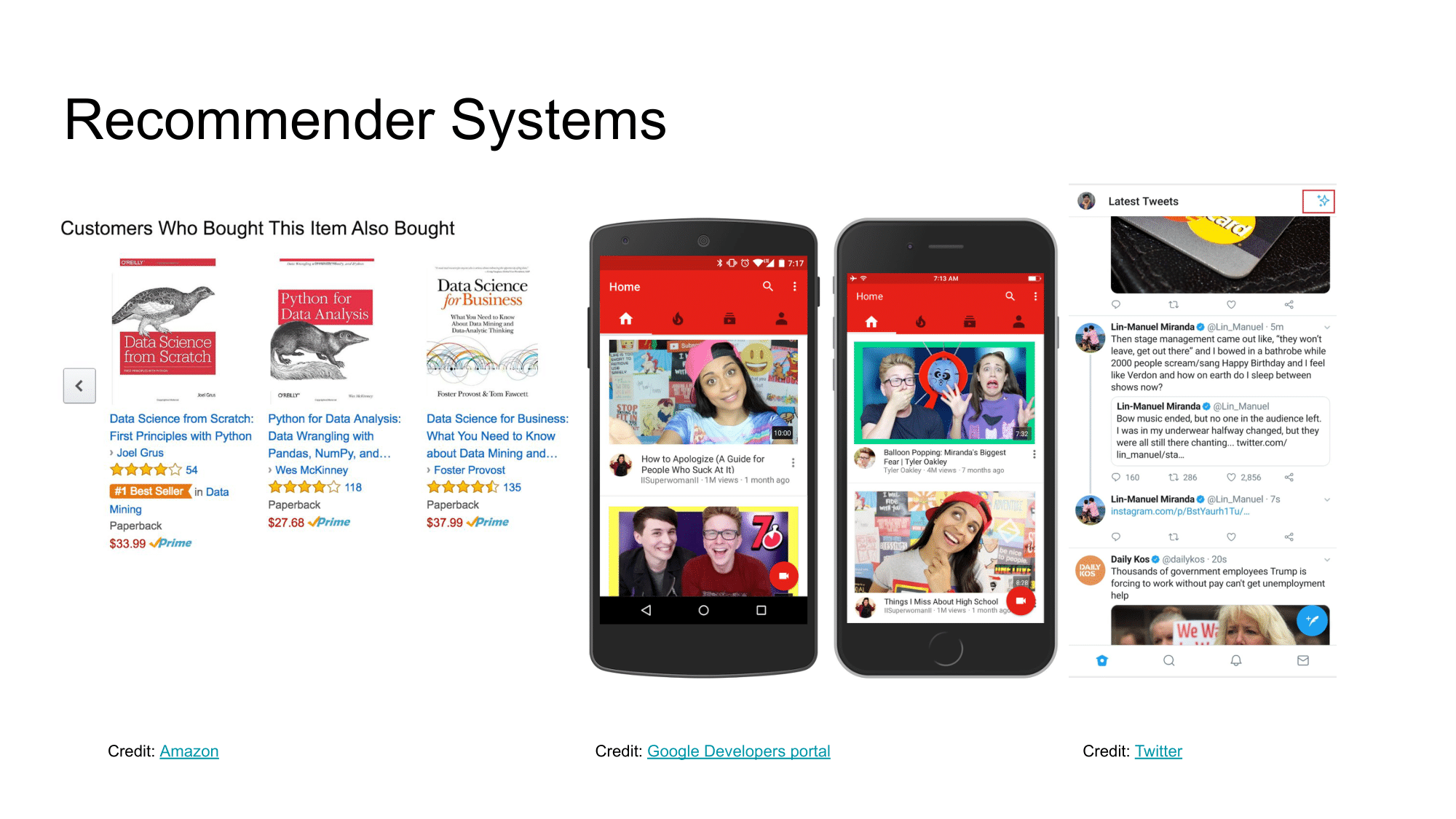
You probably already know that recommender systems are all around you:
- they select and rank products in marketplaces (Amazon, Yandex) and movies on Netflix/Disney to find the most relevant one to you,
- they prepare podcasts and select the next track/video on Spotify/Youtube to suit your personal preferences,
- they filter your feed when you scroll through Twitter/Instagram/VK to show the most important news to you.
As a result, today’s recommender systems affect almost every aspect of user experience. And the current demands for personalized user experience and advances in machine learning are constantly pushing the field towards new scientific advances.

The most standard and most popular method in recommender systems is collaborative filtering and the matrix decomposition method.
Let’s say we’re making a recommendation system for a bookstore. The idea of collaborative filtering can be described as:
- if users A and B both like books X, Y, Z,
- and user A left a positive review about the new book K,
- we would like to recommend it to user B,
- on the assumption that their interests are similar.

The practical implementation of such an idea - the matrix decomposition method - is very straightforward:
- we collect matrices of user interaction with items,
- and trying to approximate this matrix using trainable representations for users and items,
- when multiplying the vector representation of user A and the vector representation of item B, one can get their approximate “compatibility” rating from our matrix.
As a result of the method, we want
- learn how to accurately predict the current compatibility ratings that we already know about,
- make assumptions about the missing/unfilled values in this matrix and use these assumptions for future recommendations.
Recommender systems and tape influence
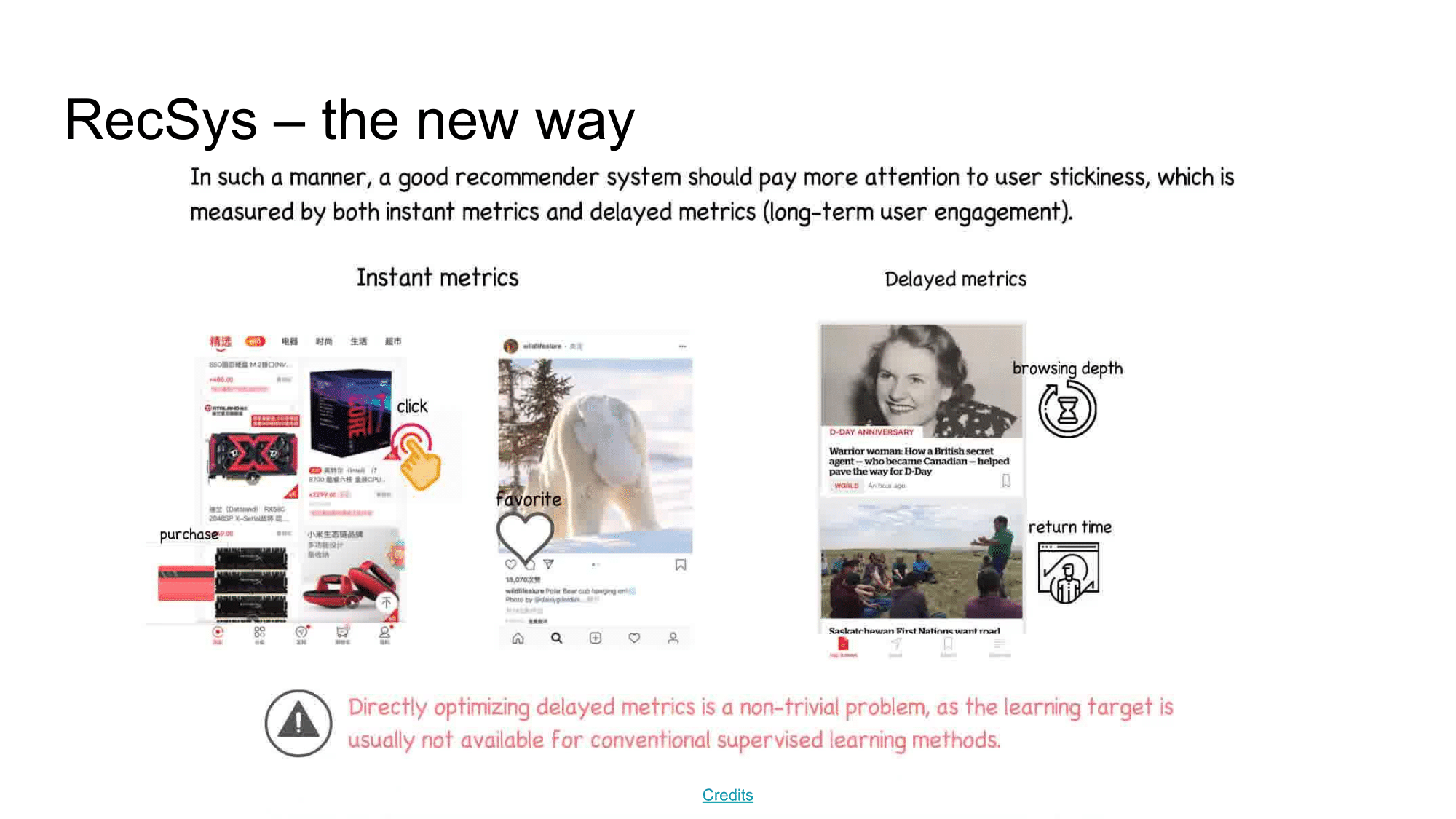
Today, the user experience changes from a static user-item-cart to a dynamic live feed. With this approach, it becomes increasingly difficult to apply collaborative filtering techniques. More specifically, the transition to such a dynamic user interaction method has raised new questions for recommendation systems usage. For example,
- how could we personalize the user’s experience during their session? How to take into account his global preferences and understand his current, short-term goals?
- how does the sequence of recommendations affect the user experience during the service session?
- how will the current session experience affect the future use of the service? (delayed reward from RL)
These questions have led to the emergence of a new type of recommender systems - collaborative, interactive recommenders (CIRs). CIRs are recommendation systems that optimize a sequence of user interactions rather than one specific recommendation.
Developing CIR recommender systems in the Deep Learning, Supervised Learning paradigm can face many practical difficulties. At the same time, the Reinforcement Learning approach is the de facto standard for optimizing sequential decision-making tasks and is perfectly expandable to a framework for the user-recsystem interaction.
RL in RecSys

According to Craig Boutilier, RL methods in RecSys could allow us to understand and meet user needs with more natural and transparent interaction. Over the past couple of years, there has been a lot of progress in using RL methods on heterogeneous data - pictures, texts, sounds. Moreover, the reinforcement learning framework allows direct optimization of finite metrics without using differentiable proxy metrics.
In this way, we can see a smooth transition from Collaborative Filtering through Collaborative Interactive Recommenders to a Reinforcement Learning framework for the RecSys area.
In this review, I would like to show the scope of application of RL in RecSys and talk about the similarities between these two areas. To do this, let’s go over several articles and summarize their applicability in real life. Let’s leave the topic of using multi-armed bandits behind the scenes (it’s a well-known topic already) and focus more on the Deep Reinforcement Learning example.
Deep Reinforcement Learning in Large Discrete Action Spaces
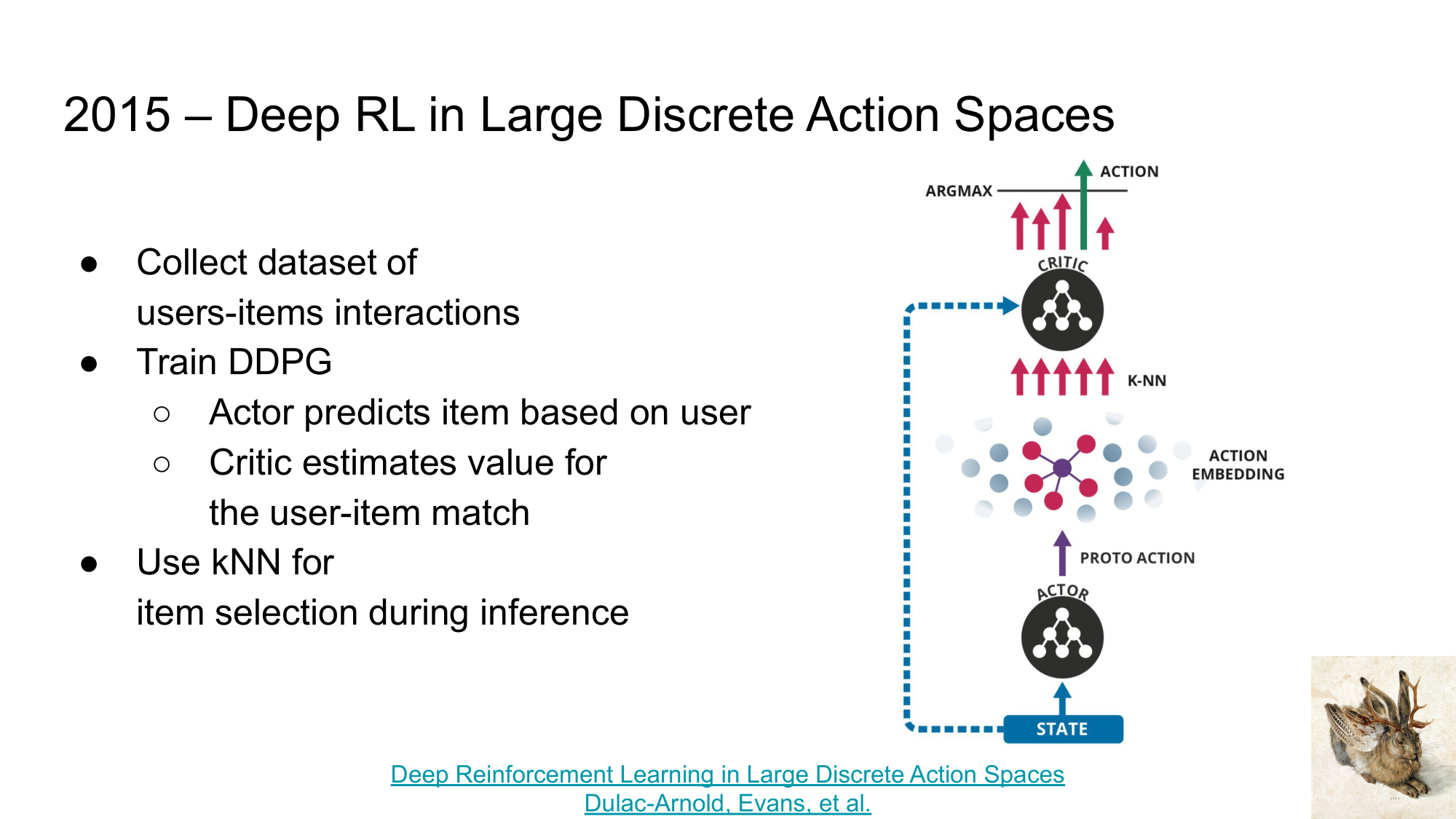
The first article I want to talk about when moving from RecSys to RL is “Deep Reinforcement Learning in Large Discrete Action Spaces” and the Wolpertinger algorithm.
The brief essence of the article is as follows::
- let’s collect a dataset of user interactions with products (as in the matrix factorization method)
- and train DDPG (Deep Deterministic Policy Gradient) on it
- the Actor task is to predict the most relevant representation of the item that the user needs to recommend, according to the user’s preferences
- the Critic task - according to the user’s representation and the item recommended by Actor - to evaluate the usefulness of such a recommendation.
After such training, we can:
- “train” kNN on our database of items that we want to recommend
- use Actor to generate “approximate” product representation for the recommendation
- through kNN, find topK recommendations from our database that are closest to the “approximate” one
- and re-rank them using Critic to select the most relevant one.
This approach is simple to implement and is a transition point between matrix factorization and reinforcement learning usage for recommendations.
PS. You can find an example of Wolpertinger on our course.
Deep Reinforcement Learning based Recommendation with Explicit User-Item Interactions Modeling
The next article I would like to draw your attention to is “Deep Reinforcement Learning based Recommendation with Explicit User-Item Interactions Modeling”.
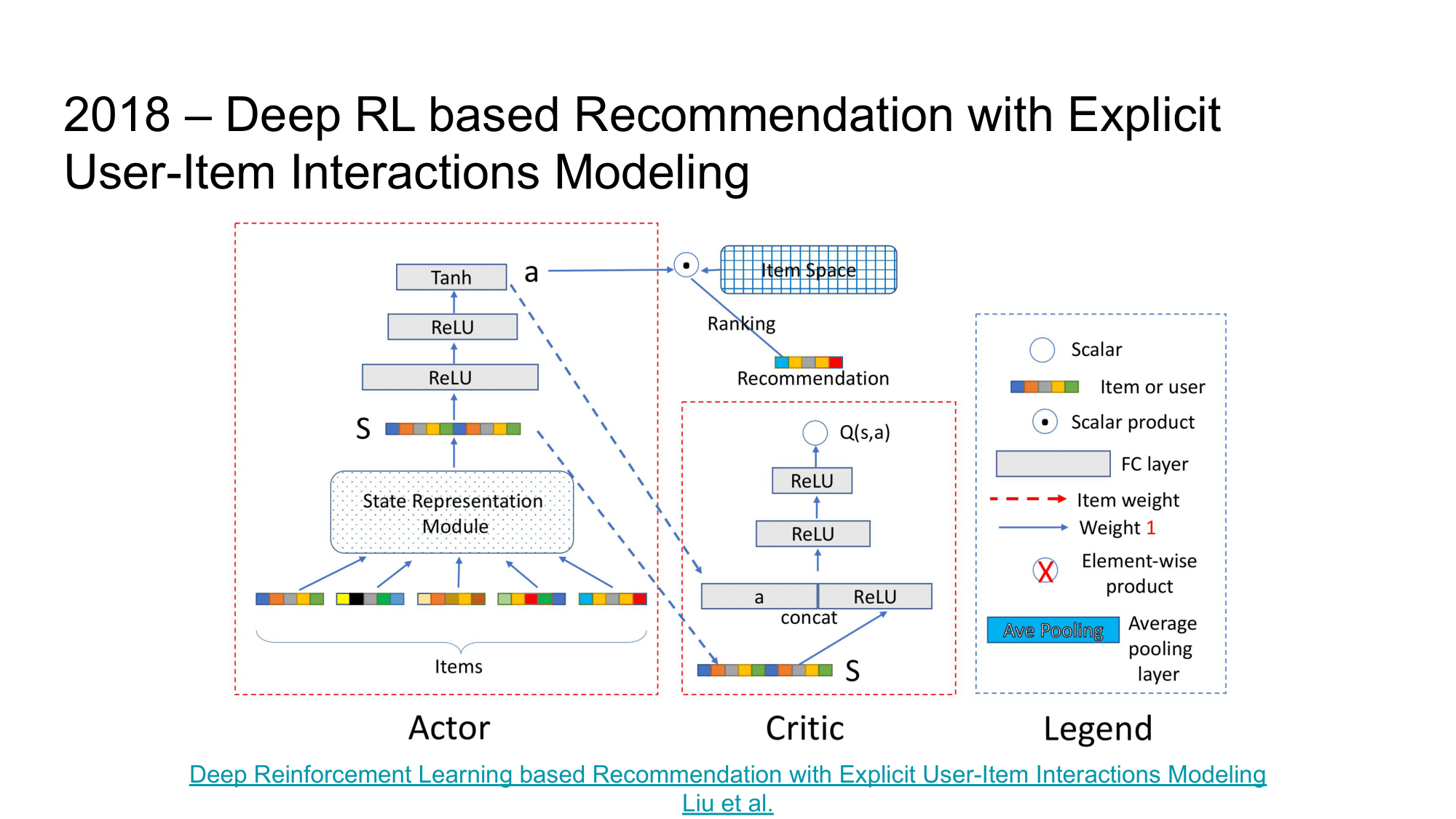
As in the previous article, it uses an Actor-Critic approach. The Actor here accepts a user’s representation and a set of items for the recommendation as input and predicts scores that rank these products to display to the user. Critic by these scores and the Actor state tries to predict the value of such a ranking.
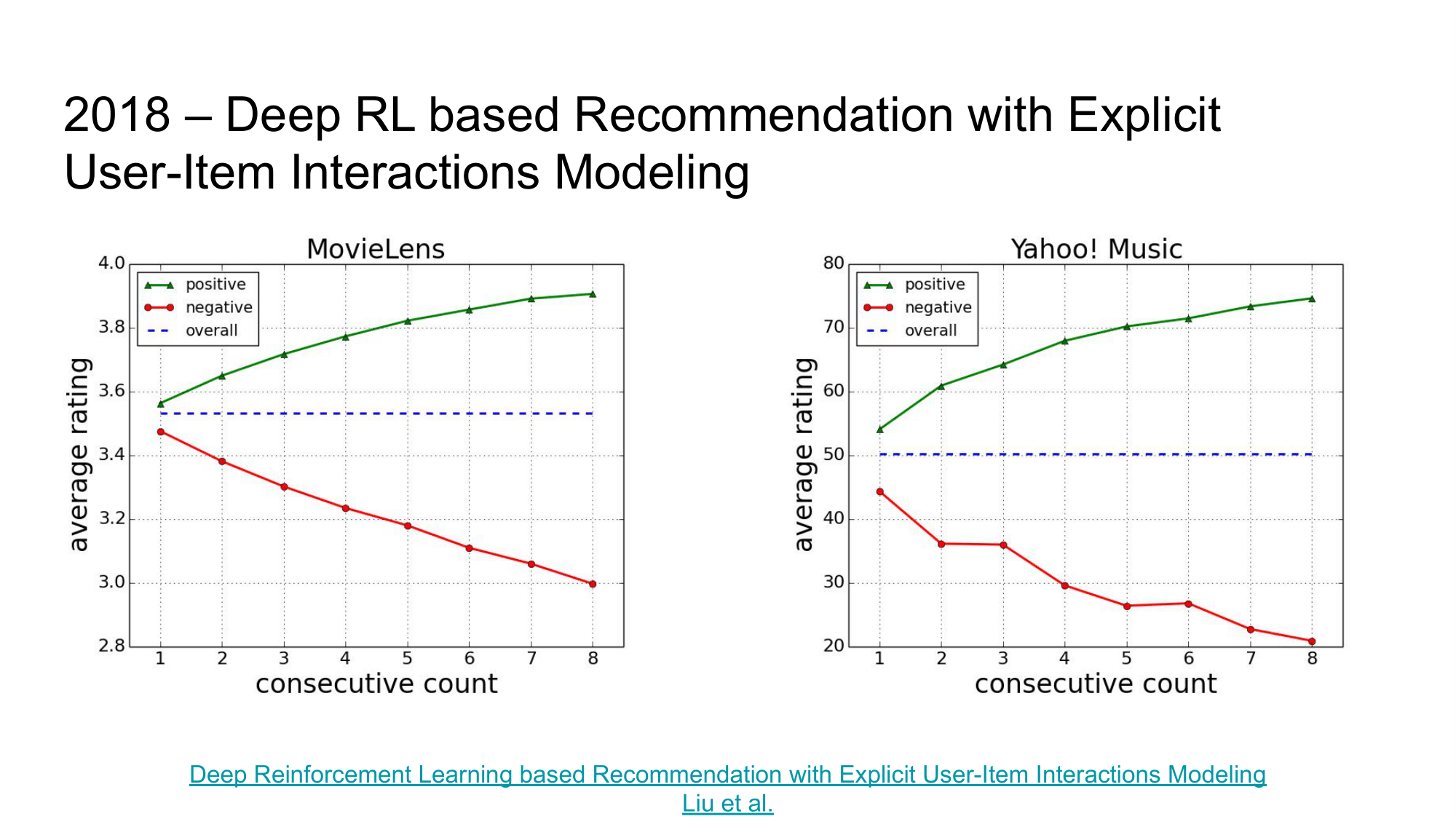
While this article takes a different architectural approach to use Actor-Critic in the recommendation task, the introductory research is also indicative of this article. The authors found a relationship between user satisfaction with the sequence of recommendations and the rating of the next sentence, i.e .:
- if the user likes the sequence of the suggested recommendations, he will most likely respond positively to the next suggestion
- if the user does not like the sequence of the proposed recommendations, he is more likely to evaluate the next proposal negatively.
This study shows that it is important for recommender systems to quickly adapt to the user’s current desires and moods and not to think only in the context of his “global preferences.”
Top-K Off-Policy Correction for a REINFORCE Recommender System
Regarding breakthroughs in the industrial use of RL in recommender systems, I would like to note the article “Top-K Off-Policy Correction for a REINFORCE Recommender System”.
In this article, the authors proposed several approaches for adapting On-policy RL methods for RecSys and showed statistically significant results when using such a system for recommendations on YouTube.
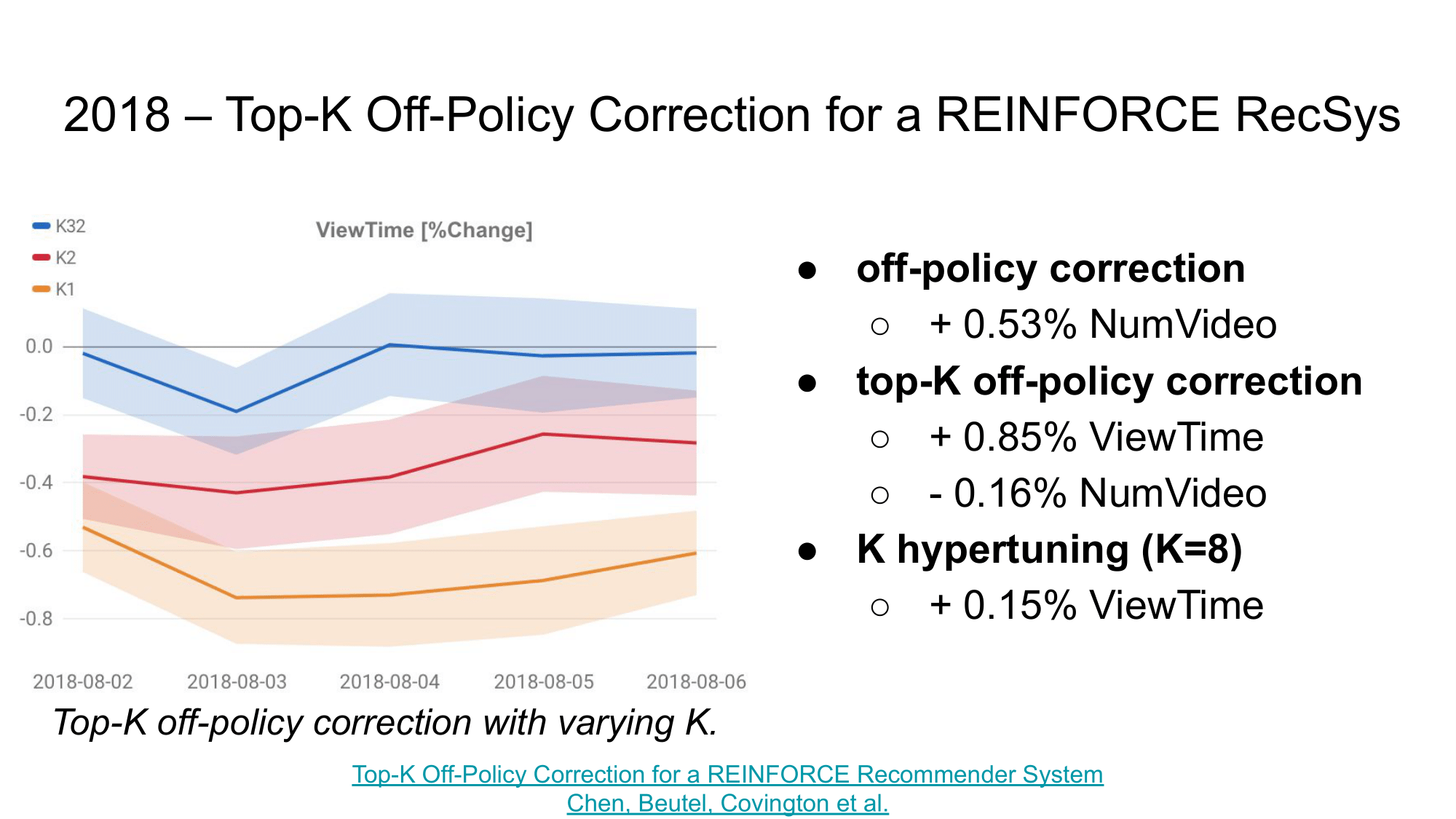
The most interesting theoretical and practical results include:
- using the on-policy RL algorithm REINFORCE for the recommendation task,
- introduction of off-policy correction to adapt this algorithm to off-policy training based on logs of interactions with users - gave an increase in the number of viewed videos by 0.53%,
- introduction of top-K off-policy correction to adapt to top-K recommendations - increased the average viewing time per session (ViewTime) by 0.85%, but decreased the number of viewed videos by 0.16%,
- iterating over the K parameter - additionally increased ViewTime by 0.15%.
As a result, the authors managed to increase the number of videos viewed and the average viewing time per session. These results provide important experimental evidence for the use of reinforcement learning in large recommendation systems like Youtube, with millions of users and millions of recommendation documents.
Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
Continuing to develop the topic of using RL in recommendations on Youtube, the authors went further in their next article, “Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology” offered a detailed analysis of the methods they proposed.
Considering the article’s depth - it takes about 30 pages - I will omit its “short description” and advise only those who are really interested in reading it.
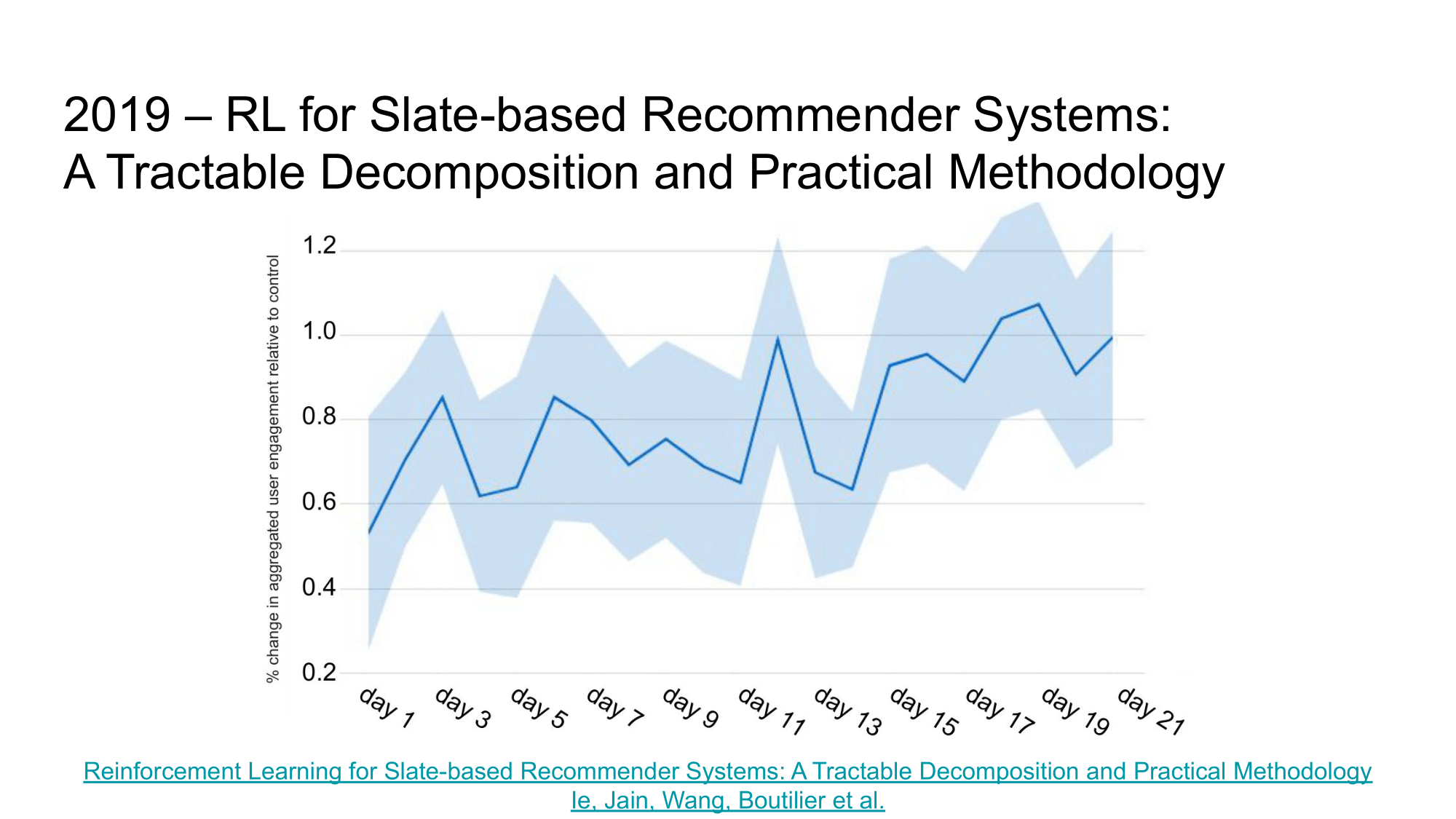
In their work, the authors compare 2 approaches to recommendations on Youtube:
- MYOP-TS, which optimizes short term user response - pCTR,
- SARSA-TS LTV which optimizes long-term user engagement.
Based on the experiment results, SARSA-TS LTV managed to show an increase of 1% according to the user engagement metric. This article proves the possibility of direct optimization of non-differentiable LTV metrics using reinforcement learning in the recommendation problem (even in such large systems as Youtube).
RecSim: A Configurable Simulation Platform for Recommender Systems
Finally, I would like to draw your attention to the article “RecSim: A Configurable Simulation Platform for Recommender Systems”, which implicitly continues previous studies.
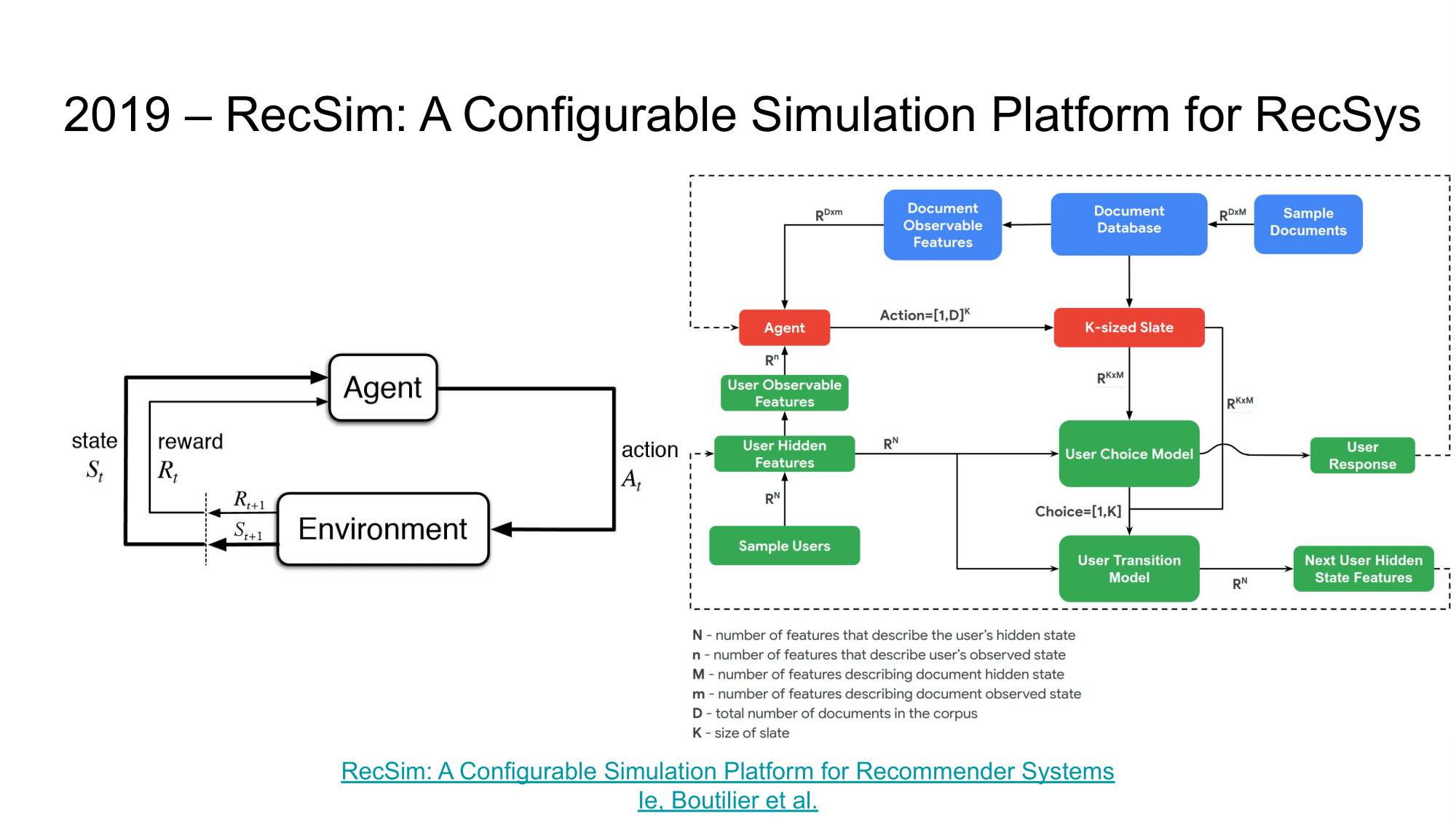
One challenge with RL applications in RecSys is that most studies are designed and evaluated using static datasets that do not reflect the sequential interaction of a recommender with the users. This makes it difficult to evaluate even basic RL algorithms, especially when we thinking about the long-term implications of some new recommender policy. The ability to simulate user behavior in a certain environment, develop and test new recommendation algorithms, including using RL, can significantly accelerate research on the applicability of RL in RecSys.
In this article, the authors present a RecSim - RL environment that simulates the interaction of a recommender with an environment consisting of a user model, document model, and user selection model. A more detailed description can be found on Github. I would like to believe that thanks to such libraries, RL research in RecSys will become more accessible, understandable, and more standardized thanks to a larger community.
Conclusion
From the above articles, it can be seen that research on the use of RL in recommendation systems is already actively used in large projects/products and is already helping us.
Should you use RL in your recommendations? Of course …. it must be tested and verified. It would be best if you started from the task’s conditions and requirements, rather than from the technologies. Compare it with baselines, start with simple solutions (take an example, RecSim with Wolpertinger from the course), read all the articles from this review, evaluate the complexity of implementation and the usefulness of such a system.

I hope this overview has been a good introduction to RecSys.RL area for you. Relevant and long-term recommendations to you!