Animus

Introduction
Recently, I released Animus - yet another package for your ML/DL/RL experiments, which we will talk about today. Long story short, in this post, we will dive into the idea behind Animus, why we need it, and how you could benefit from it in your projects.
But first, let’s dive into my background, so we can all be on the same page. During my career, I experimented with all types of machine, deep and reinforcement learning. Starting from ML, I dive into dl-heavy CV and NLP. Then I got some experience with RL during the 2017-2019 NeurIPS.RL competitions. In the end, to organize my dl and rl knowledge, I released Catalyst and Catalyst.RL packages and still contributing a lot to the first one.
Hint: For those interested in MLE career development, dl-framework maintenance is a great way to develop your skills and understand the internals of “fit-predict” pipelines and all the available pitfalls of the engineering side of deep learning. A great theory with poor realization is still only a great theory.
Starting 2021, my research interests shifted to a more sequential domain such as Reinforcement Learning, Recommender Systems, and Time Series. The most exciting part of the latter two domains is that the statistical and ml-based baselines there are hard to beat with dl methods, and you have to benchmark with them all the time. Unfortunately, many current ML/DL frameworks do not support such an opportunity, so here we come to the Animus.
Animus
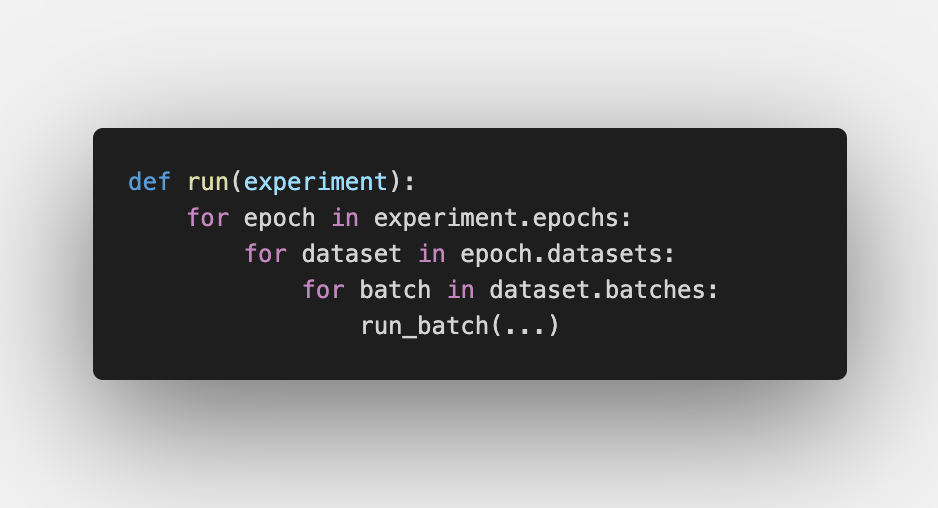
The first motivation and a significant feature of the Animus - is its ability to handle any ML/DL/RL experiment. Honestly speaking, Animus is just a general-purpose for-loop experiment wrapper. It highlights standard “breakpoints” in ML experiments thought IExperiment abstraction and provides a unified interface for them, and that’s it. You could natively evaluate heuristic/ML/DL or even RL methods in the same way, within the same interface for all your experiments.
Another core feature of the Animus is dependencies. Animus uses only pure python primitives and thus does not have any dependencies at all! While many high-level deep learning frameworks try to simplify the interface with new syntactic-sugar abstractions, it requires more and more dependencies, which could become unbelievably complex for large projects. Sometimes even tqdm could break your torch source code. Keeping this in mind, Animus was developed in no-deps required manner.
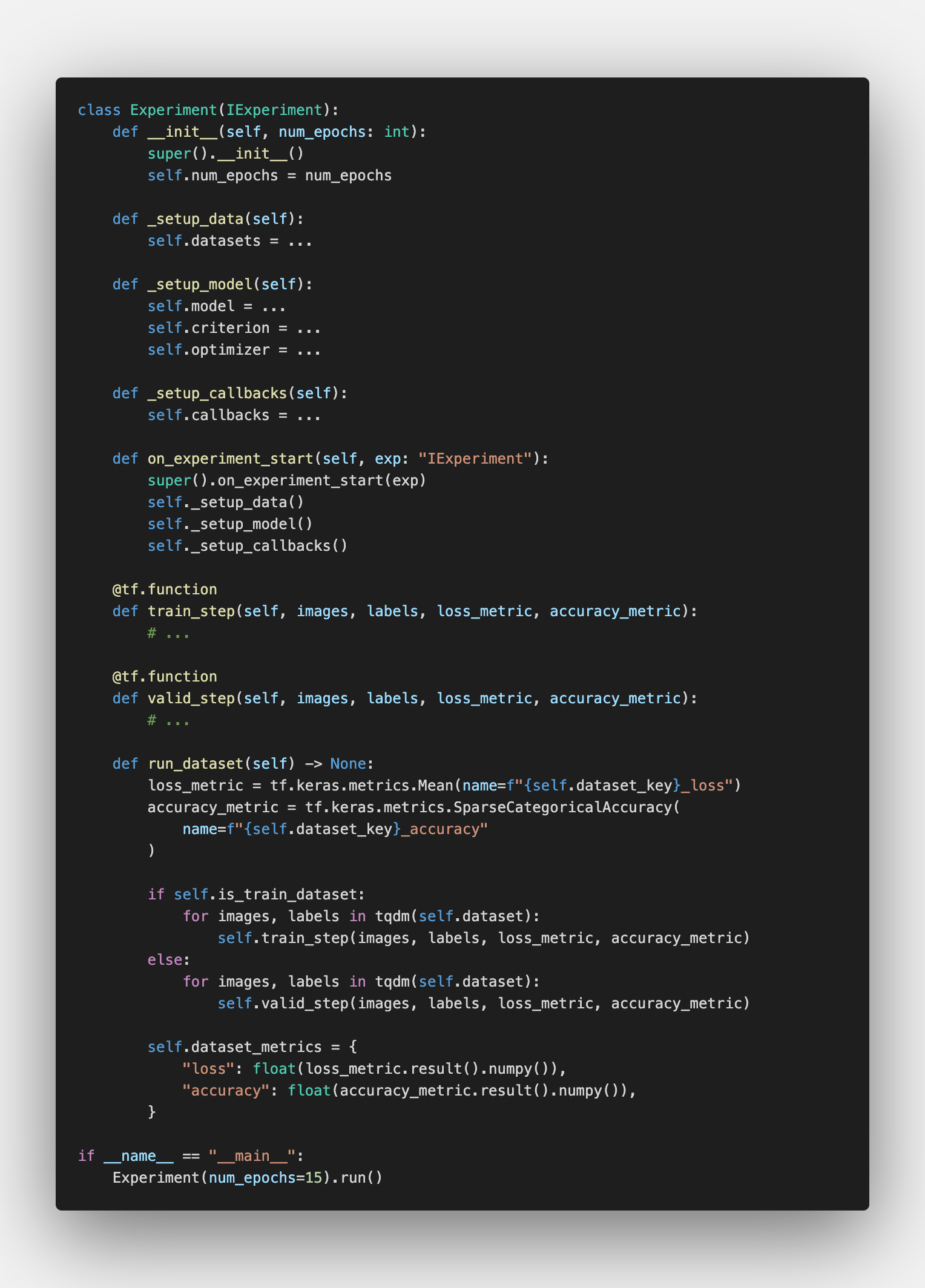
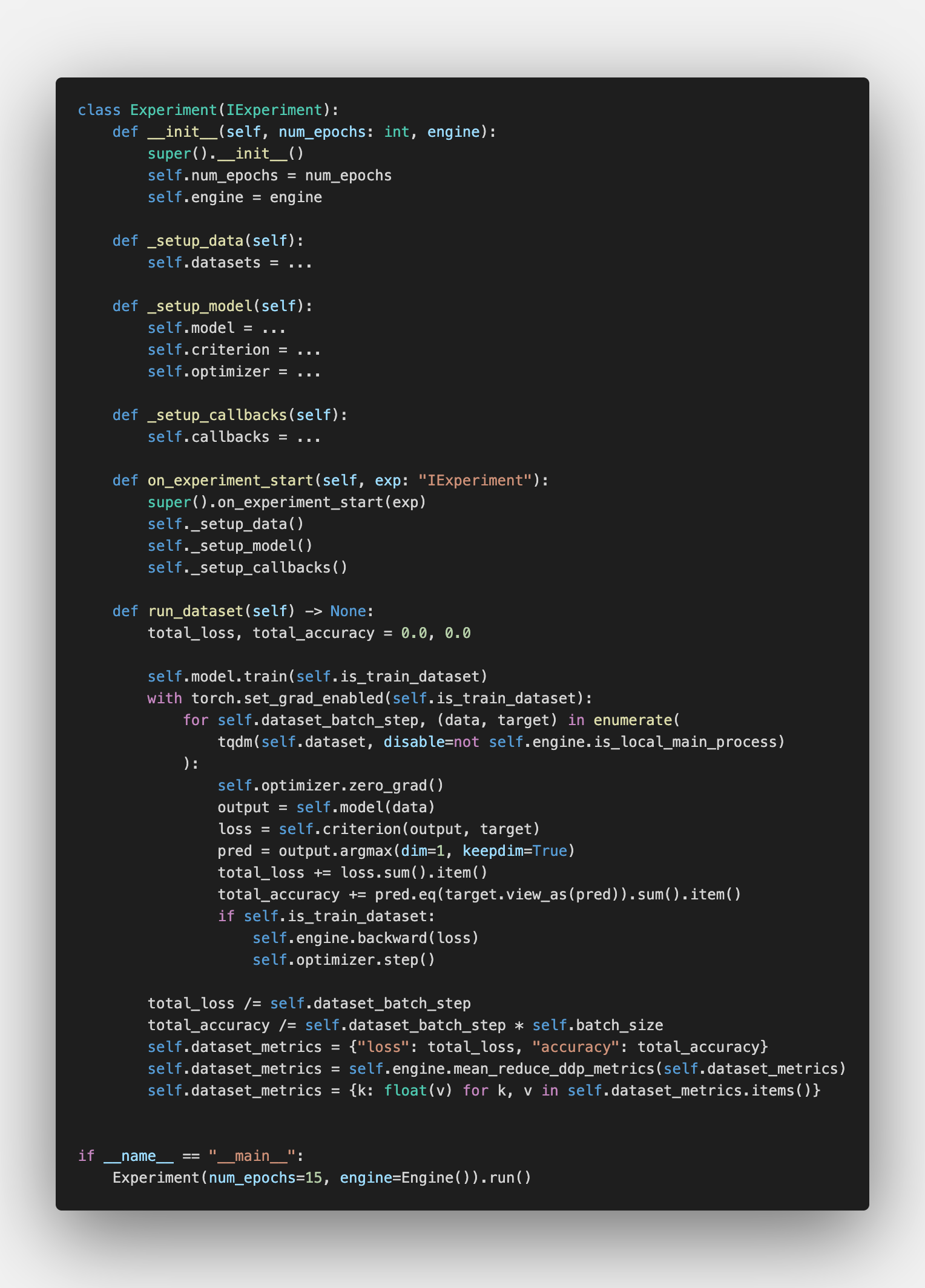
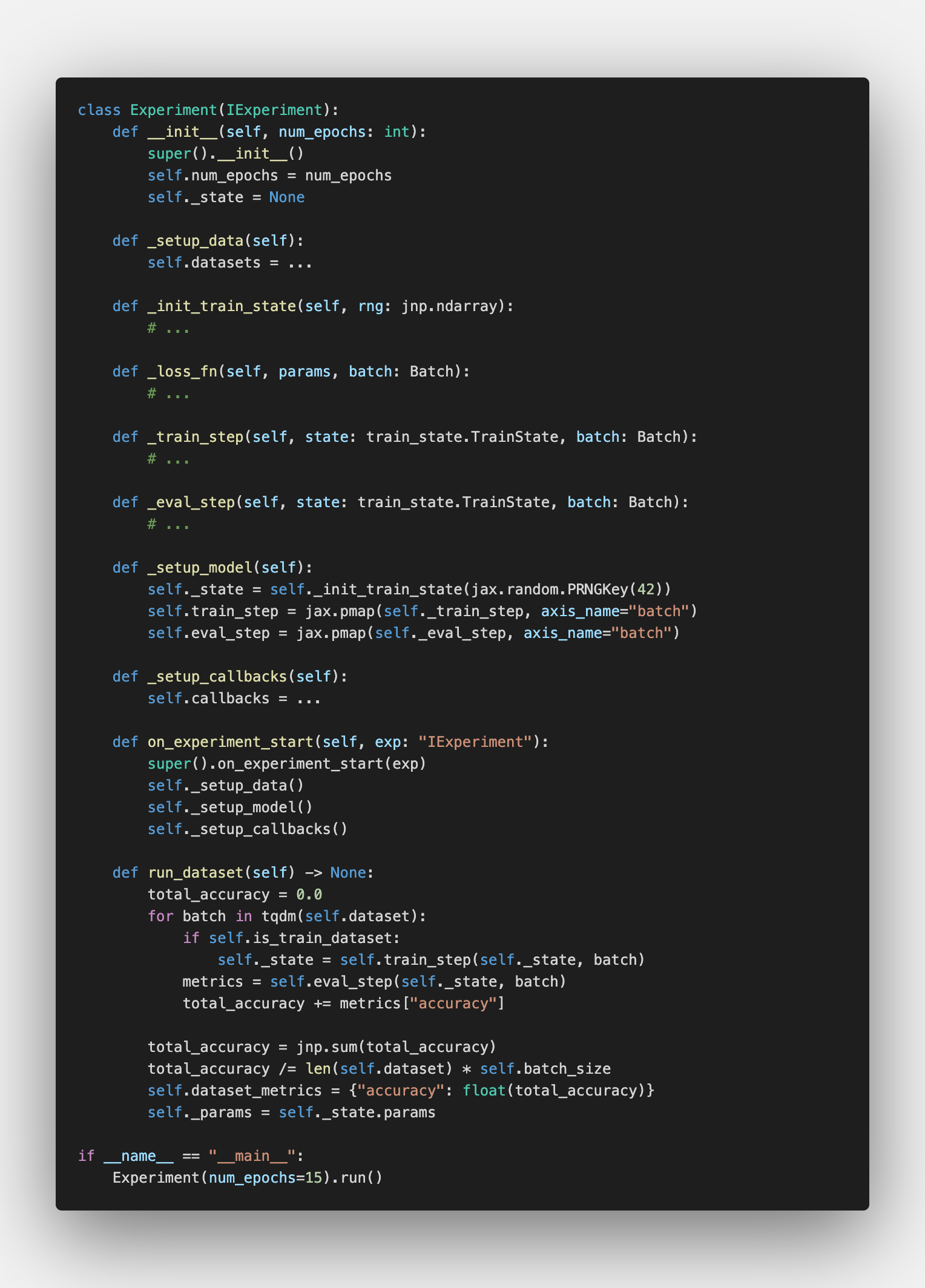
Finally, combining the lack of dependencies with simple “breakpoints”-interface, we could get something completely novel, in terms of ml frameworks, of course. We could compare the performance of different DL-backends such as PyTorch, Jax, or TensorFlow. For example, we could run the same MNIST example on Jax, PyTorch, or Keras (TensorFlow) with the same data loading pipeline from PyTorch (I am a big fan of the DataLoader API).
Alternatives
Speaking of the deep learning libraries, there are plenty of high-level frameworks: Catalyst, Ignite, FastAI, Keras, etc. As an author of the one of them, I am 100-percent sure about their importance to the community: they give newcomers an easy start, industry - useful community-proven standarts, and help with the dl reproducibility issues. On the other hand, any custom pipeline, which does not follow the predefined framework logic could break the syntactic sugar of the high-level API and force you to write low-level code with extra constrains from the framework. While Catalyst, for example, support such customisation through get_loaders, get_model, handle_batch, not all the alternatives could handle that with ease. Moreover, I still found it as “internal code digging” a bit. Simple, yet digging.
Animus tries to keep it simple, distinguishing the core features, like metrics and breakpoints, from all the complexity of the machine learning. It would not “help” you with logging to all available monitoring systems, or “scale” your code to the cloud without any changes. It only proves your a structure to organize your code. That’s it.
Hint: There are also google/trax and deepmind/jaxline projects, that follow the same idea.
Conclusion
Long story short, Animus:
- highlights standard breakpoints in ML-based experiments within unified, simple interface
- does not introduce any additional requirements
- does not force you to use the only one DL framework
- allows you to mix and compare heuristic, ML, DL, RL approaches and different low-level libraries
To check more about the Animus, please follow the examples. You could find Jax, PyTorch, Keras deep learning, and reinforcement examples. Sklearn-based CEM (I am a big fan of the RL) and Wandb agents integration included. If you are interested in more tutorials - do not hesitate to open a pull request and contribute. I will be truly thankful for distributed Keras and Keras RL examples (I am not a TensorFlow expert nowadays).
If you would like to check more deep learning best practices — subscribe on twitter or telegram. Thanks for reading, and stay tuned for more!